
As aplicações que utilizam Large Language Models (LLM) normalmente intermediam as solicitações dos usuários e enviam requisições para as APIs dos provedores de modelos, como o Azure Open AI.
Esses modelos geram respostas com base no conhecimento acumulado durante as etapas de treinamento. Por isso, eles não atendem requisições que demandam informações atuais ou dados organizacionais, que geralmente ficam restritos aos sistemas da empresa. Nesses casos, as respostas podem variar, mas normalmente informam que o conteúdo solicitado não está no conhecimento do modelo e, sempre que possível, indicam onde encontrar essas informações, por meio de dicas de documentação ou sites. Dependendo das configurações do modelo, ele também pode gerar dados na tentativa de atender à solicitação, mesmo que essas informações não representem a realidade (um cenário indesejado).
Desafios no Acesso a Dados Organizacionais
Nesse ponto, os profissionais começam a levantar dúvidas. Como o modelo de base, com o conhecimento inicialmente acumulado, não atende às requisições sobre dados da organização, precisamos buscar alternativas. Como configuramos as aplicações para aumentar o conhecimento dos modelos? Qual modelo melhor se adapta a essa tarefa? Podemos usar bancos de dados relacionais e não relacionais? Como consultamos bancos com centenas de milhões de linhas sem comprometer o desempenho? Essas e outras perguntas aparecem frequentemente durante a criação de sistemas com IA Generativa.
Com essas questões em mente, elaboramos este artigo para direcionar e esclarecer alguns desses pontos.
Como Aumentar o Conhecimento dos Modelos
Primeiro, como podemos aumentar o conhecimento dos modelos de base?
Encontramos algumas alternativas. Entre elas, destacamos a técnica Retrieval Augmented Generation (RAG). Essa técnica atribui uma nova responsabilidade às aplicações. Agora, além de tratarem as mensagens dos usuários e interagirem com as APIs dos modelos, elas consultam repositórios para buscar dados que atendam às solicitações, como, por exemplo, bancos de dados, sistemas de arquivos ou APIs.
Durante a implementação do RAG, a aplicação consulta um ou mais repositórios. Não enfrentamos limitações nesse processo. Inclusive, a aplicação pode acessar repositórios isolados, distintos e com informações não relacionadas.
Tratamento e Enriquecimento de Dados com RAG
Durante as consultas, compilamos os dados obtidos e, dependendo do tipo de aplicação, tratamos e adequamos essas informações. Ao final, fornecemos esses dados ao modelo junto com a solicitação do usuário e outras instruções (prompts), aumentando assim o conhecimento do modelo.
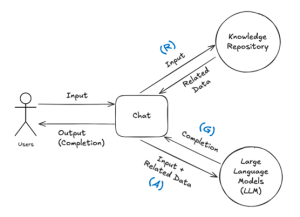
A partir desse ponto, os desenvolvedores geralmente se perguntam: como consultar grandes bancos de dados sem comprometer o desempenho da aplicação?
Desempenho em Consultas a Grandes Bases de Dados
A tarefa que pode se tornar complicada, principalmente quando os dados são utilizados por aplicações de conversação, nas quais, o tempo de resposta é uma variável importante. Sendo assim, não podemos, a cada solicitação, obter todos os dados de um banco de dados, compilar e fornecer ao modelo. Precisamos, de forma prática, extrair somente os dados relevantes.
Preparação de Bases com Embeddings
Com esse propósito, as bases de conhecimento precisam ser previamente preparadas para que as solicitações sejam recebidas.
Por exemplo, ao preparar bancos de dados relacionais, as equipes adicionam colunas específicas para armazenar vetores (também chamados de embeddings), que são gerados por modelos específicos. Esses vetores permitem que as consultas semânticas identifiquem e retornem apenas os dados mais relevantes dentro do contexto da solicitação. Assim, as aplicações consultam grandes volumes de dados de forma eficiente.
Escolha das Ferramentas Ideais
Muitas pessoas também têm dúvidas sobre qual é a ferramenta ideal para usar.
A reposta possui grande relação com a estrutura dos dados. Se, por exemplo, a infraestrutura da aplicação está hospedada no Azure e os dados a serem consultados possuem estrutura mais bem definida, podemos utilizar recursos como o Azure Database for PostgreSQL (Flexible Server) ou Azure SQL Database. Se, por um outro lado, a aplicação precise consultar dados que não possuem padrão definido (documentações, livros, mensagens …), podemos, por exemplo, utilizar recursos como o Azure AI Search e Azure Blob Storage.
Acreditamos que este material ajudou você a entender melhor como explorar dados com IA Generativa.
Até o próximo Post.
Por Luciano Gambato

