
Olá, pessoal!!
Hoje vamos conhecer um pouco do Data Swamp, onde o nome que comumente é atribuído para um conjunto de dados que não possui políticas para definir a forma como os dados devem ser organizados, armazenados e consultados. Normalmente, esse problema ocorre durante a utilização de Data Lakes, onde não foram definidas políticas para organizar os arquivos, tampouco definições de segurança para restrigir os níveis de acesso às informações contidas nesses repositórios.
Para melhorar o entendimento deste tópico, sugerimos a leitura do artigo “Data Warehouse, Modern Data Warehouse, Data Lake e Lakehouse”, no qual estas estruturas de análise de dados são explicadas.
(https://www.cdbdatasolutions.com.br/blog/data-warehouse-modern-data-warehouse-data-lake-e-lakehouse/)
Abaixo elencamos algumas boas práticas na construção de uma estrutura de Data Lake.
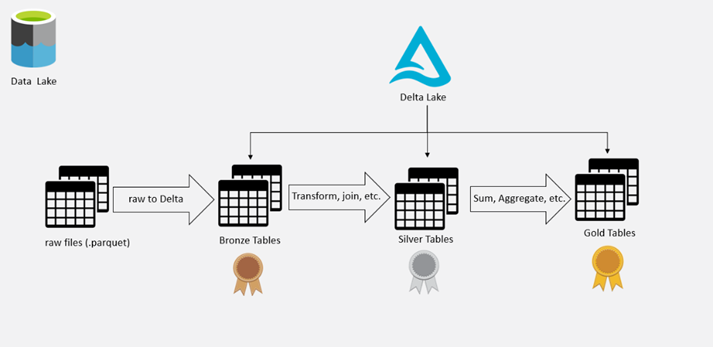
1 – Trata-se da criação dos layers ou níveis de refinamento da informação. Para construirmos uma estrutura onde diversas equipes consigam utilizar os mesmos dados para criar análises distintas, precisamos que os dados estejam armazenados conforme foram gerados na origem. A partir dessa definição, surge o primeiro layer do Data Lake que é chamado de raw. Nesse nível é gravada a informação conforme a estrutura que a origem apresenta, trazendo agilidade no processo de gravação e garantindo que nenhuma informação, que possa ser pertinente para as análises, seja perdida.
Nos próximos três níveis é utilizado um Storage Layer para fazer o gerenciamento dos arquivos armazenados. Portanto, o segundo nível é chamado de bronze, nele é feita a cópia dos dados que estão na camada raw para a camada bronze trocando o formato para Delta Lake, por exemplo. Nessa etapa não deve ser feito nenhum tipo de tratamento nos dados, ou seja, os dados serão armazenados conforme a origem (as-is). (Você pode encontrar mais informações sobre o Delta Lake em: https://docs.delta.io/latest/index.html)
O próximo nível é chamado de silver. Nele são salvas tabelas com um nível maior de refinamento, que podem ser representadas pela união de uma ou mais tabelas armazenadas no layer bronze ou tratamento dos tipos de dados.
O último nível é denominado gold. Nele são armazenadas as informações prontas para o consumo. Essa camada, geralmente armazena dados sumarizados e agrupados, diferente do nível silver que preza por manter um nível maior de detalhamento.
O processamento dos dados dentro do Data Lake deve seguir a sequência “raw – bronze – silver – gold”.
Abaixo temos uma representação gráfica para ilustrar a estrutura do Data Lake + Delta Lake:
2 – Podemos citar a definição das políticas para remoção de arquivos que não são mais úteis para as análises, tarefa indispensável para construir uma boa estrutura para análise de dados. Essa atividade é importante para possuirmos um ambiente enxuto, no qual os usuários consigam localizar com facilidade os dados e menos informação precise ser processada. Também temos o tratamento de arquivos que são considerados históricos e que não precisam ser acessados com frequência, eles podem ser movidos para uma estrutura que chamamos de archive.
3 – A partir da definição dos layers, pastas e organização dos arquivos, podemos definir quais usuários tem permissão para leitura e escrita nos diferentes níveis. Essa atividade é importante para garantir que nenhum usuário modifique arquivos que são utilizados em pipelines de dados, acesse dados sem autorização ou que armazene arquivos em locais errados. Esse pode ser considerado um dos pontos mais críticos quando olharmos o assunto dessa nossa discussão. O Data Swamp ocorre quando usuários sem instrução manuseiam dados de forma errada, por isso a importância de termos um alinhamento entre todas as equipes que utilizam o Data Lake, como principal ferramenta para armazenamento e controle dos dados da organização.
Com essas dicas e boas práticas é possível iniciar a construção de um Data Lake organizado, aplicando ações para prevenir que uma estrutura que inicialmente deveria ser um Data Lake bem estruturado, torne-se um ambiente caótico, onde os usuários perdem a confiança na veracidade dos dados e passem a criar as suas próprias formas para analisar as informações, tornando o processo de análise descentralizado.
Para finalizar, lembramos que no mercado existem algumas ferramentas que auxiliam nos processos de documentação e descoberta automatizada dos dados, como por exemplo o Microsoft Purview, que está disponível como serviço no Azure (PaaS) e pode ser utilizado tanto no mapeamento de estruturas de SGDBs, como SQL Server, Oracle etc., como também em estruturas de Data Lake. (Você pode encontrar mais informações sobre essa ferramenta em: https://azure.microsoft.com/en-us/services/purview/).
Esperamos que este post tenha sido produtivo!
Até a próxima 🙂

