
Nesse artigo iremos falar sobre uma feature que muitos DBAs estavam ansiosos, o backup e restore dos databases para o S3 da AWS nos moldes que hoje realizamos no Azure, ou seja, sem a necessidade de utilizarmos o AWSCli. Trata-se de um preview, sendo assim, mudanças poderão ocorrer.
Como recordar é viver, desde o SQL Server 2012 temos a opção de realizar o backup e restore diretamente no Azure, possibilitando assim um nível maior de segurança no que tange à segurança dos dados, hoje um bem de valor inestimável.
Com a crescente demanda por clouds públicas, surgiu a necessidade de realizarmos backup e restore em outros players, sem a necessidade de implementarmos rotinas complementares em outras linguagens. Sendo assim, foram realizados ajustes no REST API da engine do SQL Server, possibilitando que a mesma API pudesse realizar o mesmo processo para o S3 da AWS.
Os passos são os mesmos usados para gravar os backups em um blob do Azure. Antes de qualquer configuração no SQL Server, é necessário realizar todas as configurações no lado do AWS, como a criação do bucket, da política com as permissões necessárias (ListBucket e PutObject) para efetuar o processo de backup e restore, e o usuário que receberá a política criada anteriormente. Já no lado do SQL Server, temos que criar uma credencial usando informações do AWS. Nesse artigo não entraremos no detalhe das configurações do S3, para mais informações, acessar a documentação do player. (2)
A região default do bucket é o us-east-1, sendo assim, não é necessário indicar a região em nossa URL. A título de teste, em nosso laboratório utilizaremos uma região diferente para que possamos observar como ficará o comando.
A sintaxe para o backup no S3 da AWS é a mesma que utilizamos para o Azure, salvo que, na URL, devemos sempre iniciar a mesma com s3, dessa forma a API interpretará que estamos direcionando nosso backup para o S3.
BACKUP DATABASE <NomeDatabase>
TO URL = ‘s3://<endpoint>:<port>/<bucket>/<NomeArquivo>.bak’
Podemos complementar a sintaxe acima com outros parâmetros, como por exemplo:
– Compression
– BlockSize
– BufferCount
– Entre outros (1)
A sintaxe para o restore segue o mesmo princípio que já conhecemos e, assim como no backup, temos que iniciar nossa URL com s3.
RESTORE DATABASE <NomeDatabase>
FROM URL = ‘s3://<endpoint>:<port>/<bucket>/<NomeArquivo>.bak’
No Azure temos os block blobs para dividir os arquivos em blocos. No S3 devemos dividir os arquivos em várias partes (bloco). Cada arquivo no S3 pode ser dividido em até 10.000 (partes), com seu tamanho variando de 5 Mb a 20 Mb. A definição do tamanho de cada parte é realizada através do parâmetro MAXTRANSFERSIZE, cujo valor default é de 10 Mb. Dessa forma, se não usarmos o parâmetro em nossa sintaxe de backup ele já assumirá que cada parte terá 10 Mb.
Caso seja necessário realizar um backup de um database grande, podemos dividir o arquivo backup em até 64 URLs. Dessa forma, para termos o tamanho total do backup, será necessário realizar o seguinte cálculo: MAXTRANSFERSIZE * 10.000 * quantidade de URLs.
Agora vamos ao nosso laboratório, não esquecendo que criamos nosso bucket na região us-east-2, assim teremos um cenário um pouco diferente.
A sintaxe para criação do certificado é basicamente a mesma que utilizamos para o Azure, com dois pontos a serem considerados:
– O nome da credencial deve iniciar com s3:// e complementar com a URL (gerada no AWS), sem a parte do HTTPS;
– O parâmetro IDENTITY obrigatoriamente deverá ser S3 Access Key.
Sintaxe:
CREATE CREDENTIAL s3://<URLsemHttps>
WITH
IDENTITY = ‘S3 Access Key’
,SECRET = ‘AccesskeyID:SecretAccessKey’;
Vale ressaltar que as informações sobre a URL, AccessKeyID e SecretAccesskey, teremos no AWS.
Criando a credencial:

Script:
CREATE CREDENTIAL [S3://ancdb.s3.us-east-2.amazonaws.com/backupsql]
WITH
IDENTITY = ‘S3 Access Key’
,SECRET = ‘AKIW7BPLA:uHHbchpijpQCyjfeQum6A’;
Para nosso backup no S3 iremos utilizar o database AdventureWorks2019. No parâmetro URL, indicamos o nome da credencial, pois trata-se do caminho para o S3 + o nome do arquivo de backup.
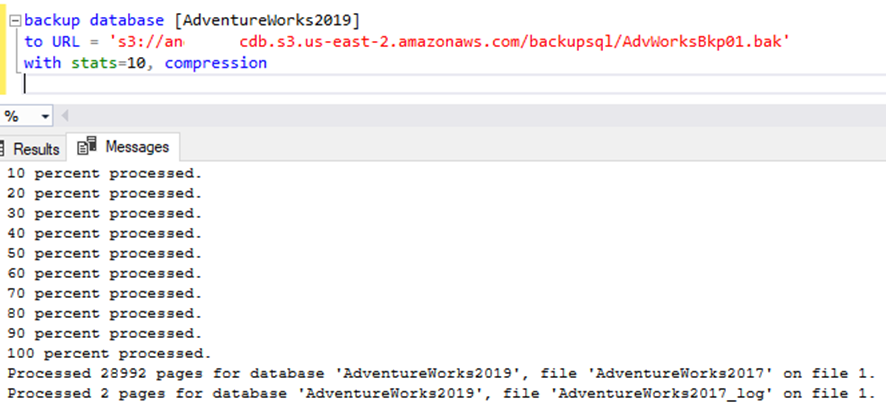
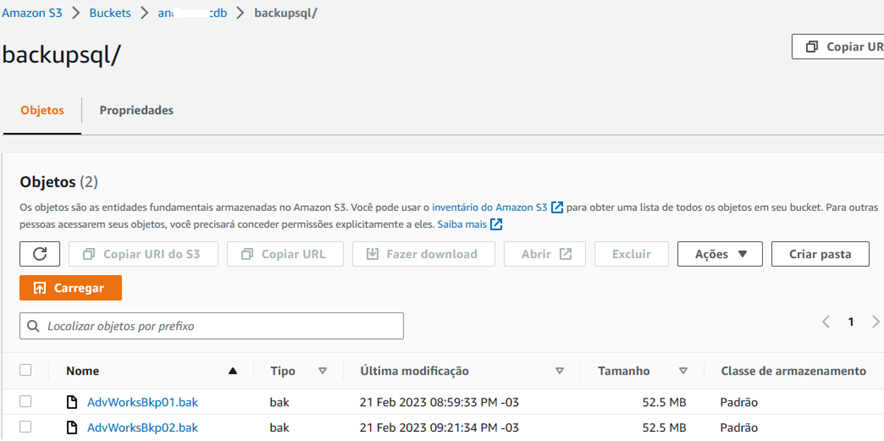
Esse processo é válido para backups diferenciais e de TLogs, assim como backups copy_only.
No caso do restore, seguimos basicamente o mesmo procedimento do Azure. No exemplo iremos realizar um restore usando o backup que realizamos acima. Lembrando que não será necessário indicar o MAXTRANSFERSIZE no restore, pois assumirá o valor que passamos como parâmetro no nosso backup.
No print abaixo, estamos usando o Restore FileListOnly para visualizar as informações referente ao backup AdvWorksBkp02.bak

Com todas as informações, podemos proceder com o restore, conforme o print abaixo:
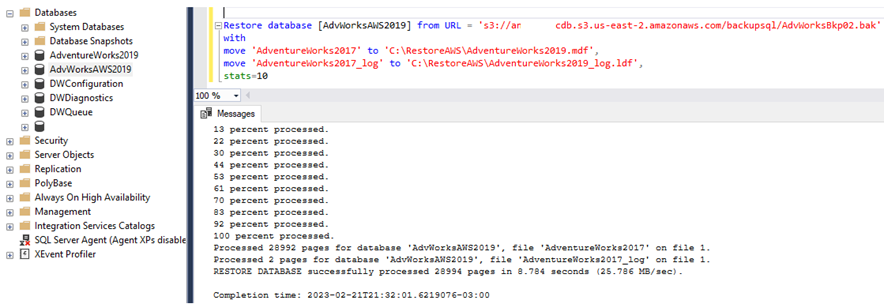

Pontos de atenção:
– Um único arquivo poderá ter até 209 Gb;
– Suporte a criptografia;
– Não existe suporte de espelhamento entre URL e Disco;
– TLS deverá ser configurado, pois o processo utiliza HTTPS;
– Compactação é recomendada (Compression);
– URL limitada a 259 caracteres;
– O nome da credencial no SQL Server é limitado a 128 caracteres;
– Não há suporte para SQL Server Express e nem SQL Express com Advanced Services.
Por hoje é isso pessoal!
Nos vemos no próximo post. 😉

